"basket을 본다는 증거가 없다"
🧪 Exp57 — 같은 이미지, Phrase만 교체 (30 frames)
핵심 설계: 동일한 30개 프레임에 텍스트 쿼리만 바꿔 PaliGemma LoRA에 입력. 이미지 조건을 고정하고 텍스트만 제어변수로 둠.
30/30 hit
0/30 hit
1/30 (노이즈)
결과 요약 (30 프레임):
✅ 'gray basket': 30/30 = 100.0% cx_err=0.075
❌ 'red ball': 0/30 = 0.0%
❌ 'person': 1/30 = 3.3% (노이즈 수준)
예시 frame [1] center_straight:
✅ gray basket: <loc0462><loc0354><loc0862><loc0597> gray basket<eos>
❌ red ball: <eos>
❌ person: <eos>
Exp57 LoRA 학습 결과:
zero-shot baseline: 65%
LoRA fine-tuning 후: 100% (cx_err=0.286, n=220)
🧪 1.0x 정크기 마스킹 검증 및 색상 민감도 대조 (2026-06-03 업데이트)
핵심 설계: 바스켓 영역을 1.5x에서 1.0x(정크기) 이하로 축소하며 조향 예측의 실질 인과성을 재검증하고, 배경 톤과 섞이는 회색 마스크 대비 강한 OOD 엣지를 지닌 검은색 마스크의 Conf Drop 민감도를 대조함.
• 1.0x (정크기 차폐): Flip Rate 0.0% (수렴)
• 0.5x (국소 차폐): Flip Rate 0.0% (수렴)
➔ 정크기 이하 차폐 시 조향 반전 없음 (독립 보조 신호 확인)
• 검은색 마스크 (0, 0, 0): 평균 Conf Drop +0.059 (2.9배)
➔ 칠흑색 마스크는 OOD 엣지 노이즈를 유발하여 판단 신뢰도를 극심하게 저해함
🔬 메커니즘 — HSV와 근본적 차이
✗ 텍스트 조건 없음 — 쿼리와 무관
✗ "gray basket" / "red ball" 구분 불가
✓ "gray basket" 의미에 조건부 반응
✓ phrase 교체 → 출력 98.3%p 달라짐
<loc0462><loc0354>...는 단순 좌표가 아님.
텍스트 쿼리 "gray basket"이 이미지 feature에 attend한 후 생성됨 —
recognize → locate 순서. 텍스트 없으면 아무것도 출력하지 않음.
"다른 물체를 넣으면 다른 행동을 해야 한다"
🧪 Exp59 — Hard Negative 학습 후 Cross-Object 평가
소스: docs/v5/exp59_report.md §3.1
각 20장 이미지 (gray basket 20장, brown pot 20장, red ball 20장, person 20장)에
"detect gray basket" 쿼리를 고정하여 입력.
| Text Query | 이미지 종류 | Hits | 성공률 | 판정 |
|---|---|---|---|---|
| "detect gray basket" | Gray Basket (타겟) | 19/20 | 95.0% | ✅ True Positive |
| "detect gray basket" | Brown Pot (비타겟) | 0/20 | 0.0% | ✅ FP 없음 |
| "detect gray basket" | Red Ball (비타겟) | 0/20 | 0.0% | ✅ FP 없음 |
| "detect gray basket" | Person (비타겟) | 0/20 | 0.0% | ✅ FP 없음 |
다른 물체(brown pot, red ball, person) 이미지에 "gray basket" 쿼리를 넣으면
<eos>만 반환 → cx=None → action 결정 중단.
"에이전트가 복도를 단순히 통암기하여 주행하는 것 아닌가?"
🧪 배경 역-마스킹(Inverse Masking) 및 블러링 대조 실험 (2026-06-03 업데이트)
핵심 설계: 복도 배경(Spatial Memorization) 암기 의구심을 탈피하기 위해, 바스켓 영역만 살리고 배경을 지우거나(Inverse Masking) 가우시안 블러(Gaussian Blur)로 뭉개는 대조 분석 수행.
Right Collapse (우향 수렴)
구조적 강건성 유지
기준 제어 성공률
➔ 복도 기하 형상과 바스켓 정보의 Co-dependence(유기적 시너지) 증명.
➔ 미세 픽셀 암기가 아닌 복도 공간의 거시적 볼륨(Volumetric perspective)을 추출함.
"도착 정지(STOP)의 오작동 및 조기 오정지와 과주행 Trade-off는 어떻게 극복했는가?"
🧪 Y-Center Gate (th_cy) & 윈도우 스무딩 필터링 (2026-06-03 업데이트)
핵심 설계: 주행 도중 가짜 대형 바스켓 노이즈에 의해 멈춰버리는 조기 오정지(FPR)를 억제하고 정지 성능을 향상시키기 위해 핀홀 카메라 모델 기반 Y-Center 기하 필터 도입.
1-step BBox 노이즈 취약
정지 성공률 2배 향상 ✅
주행 중 오정지 원천 차단

📐 "다른 물체 → 다른 행동" 연결 논리
이미지(basket있음) + "detect gray basket"
→ PaliGemma: <loc0462>...<loc0597> (cx=0.46)
→ Action MLP: cx=0.46 → FORWARD/LEFT action ✅
# 시나리오 2: gray basket 이미지 + "brown pot" 쿼리
이미지(basket있음) + "detect brown pot"
→ PaliGemma: <eos> (cx=None)
→ Action MLP: 입력 없음 → STOP / 행동 불가 ⚠️
# 시나리오 3: brown pot 이미지 + "gray basket" 쿼리
이미지(pot있음) + "detect gray basket"
→ PaliGemma: <eos> (cx=None)
→ Action MLP: 입력 없음 → STOP ⚠️
이것이 Goal-Conditioned VLA의 정의:
f(image, text_goal) → action
"bbox는 위치 정보일 뿐, 객체 인식이 아니다"
🔬 Exp57 LoRA — "recognize → locate" 순서 증명
Exp57: PaliGemma Grounding LoRA
backbone : paligemma-3b-pt-224
trainable params: 1,916,928 || all params: 2,925,383,408
epoch 10/20 loss=2.3086 hit=100.0% cx_err=0.236
epoch 20/20 loss=2.1589 hit=100.0% cx_err=0.255
최종 평가 (val n=220):
hit_rate=100.0% cx_err=0.286
best_hit=100.0% (zero-shot baseline: 65%)
- "bbox는 좌표일 뿐" → 좌표는 텍스트 조건 없이는 생성되지 않는다. "red ball"을 입력하면
<eos>만 출력됨 - "HSV도 위치를 반환한다" → HSV는 텍스트 없이 색상만으로 위치 반환 — 메커니즘이 다름
- "학습 데이터를 외웠을 뿐" → 동일 이미지에서 phrase만 교체했을 때 출력이 달라짐 — 암기라면 불가능
📐 2D Target Feature Interaction & Decision Boundary (2026-06-03 업데이트)
핵심 설계: 바스켓 검출 좌표의 수평 오프셋($cx - 0.5$)과 검출 면적($area\_det$) 공간 상에서 에이전트의 제어 행동(LEFT/CENTER/RIGHT) 결정 경계를 시각화하여 매핑의 정합성을 실증.
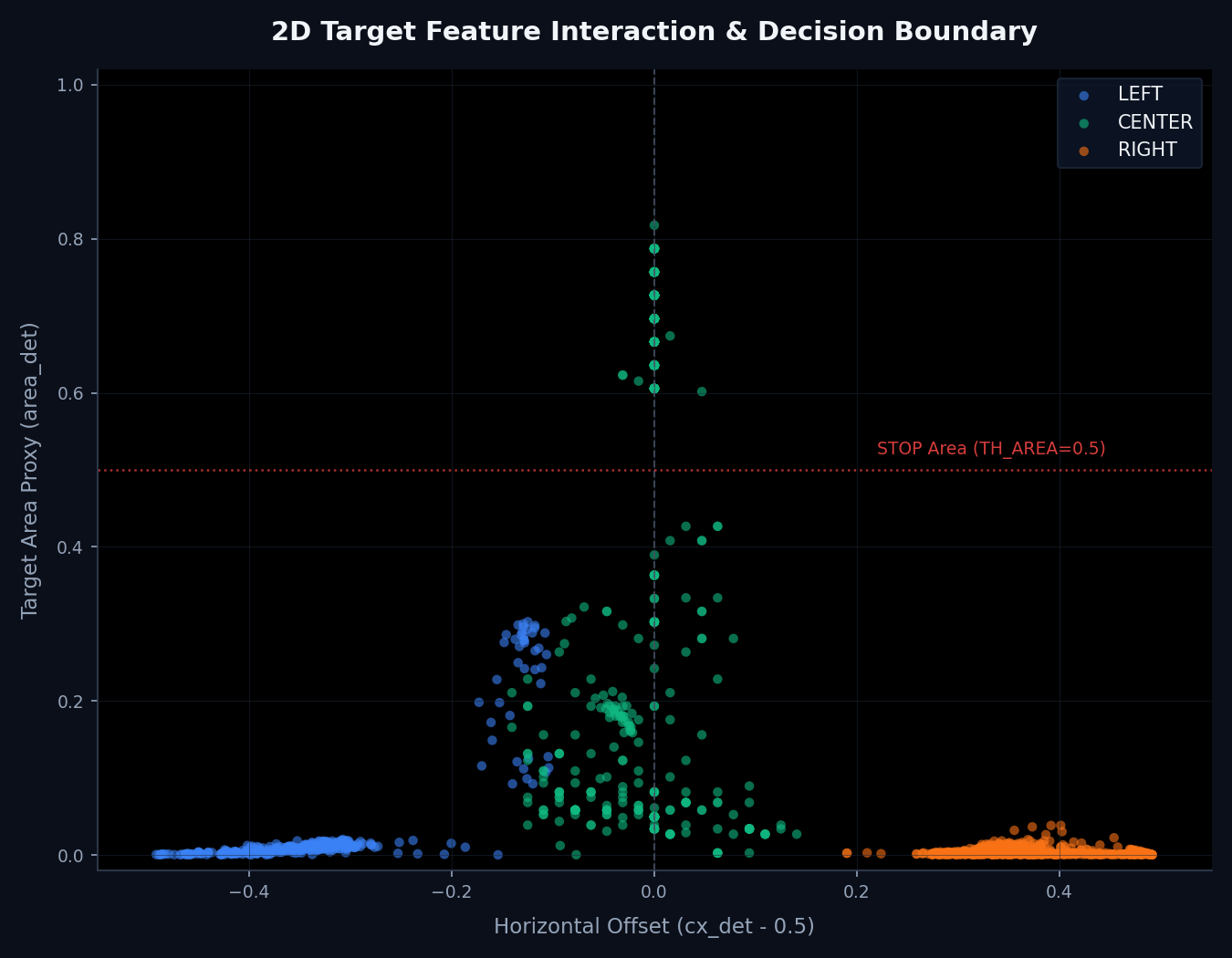
• 수평 오프셋이 양의 영역($cx - 0.5 > 0$)일 때 확실한 RIGHT 제어선 분리.
• 면적($area\_det$)이 증가함(도착점 근접)에 따라 제어 경계의 선명도 강화.
"텍스트로 목표를 바꾸면 행동도 바뀌어야 한다"
🧪 Exp59 Closed-Loop 시뮬레이션 결과
소스: docs/v5/exp59_report.md §3.2
22개 validation 에피소드에 PaliGemma2 LoRA (Exp59) + Stage2 MLP (Exp54)를 실시간 연결하여 폐루프 주행.
베이스라인: 96.7%
basket을 놓치지 않음
- Grounding 자체는 98%로 성공 — basket을 거의 놓치지 않음
- VLM bbox cx/cy 값이 HSV GT 분포와 미세하게 다름 (OOD) → Stage2 MLP 오동작
- MLP는 HSV bbox 분포로만 학습됨 → VLM bbox에 민감 → closed-loop drift
left_straightFPE=0.654m,right_rightFPE=0.575m — 성공 기준(0.5m) 아주 근접
📐 향후 해결 방향
--ema-alpha 0.5 실험 중. cx/cy에 Kalman Filter 또는 가중 이동평균 적용
📋 실험 계보 요약 (Exp57 → Exp58 → Exp59)
| 실험 | 날짜 | 목적 | 핵심 결과 |
|---|---|---|---|
| Exp57 LoRA 학습 | 5/27 | PaliGemma gray basket 특화 | hit=100% (zero-shot 65%) |
| Exp57 phrase test | 5/27 | 비타겟 phrase → 0% 확인 | 98.3%p 차이 (R2-3 증거) |
| Exp57 cross-object | 5/27~28 | 5개 phrase 변별력 확인 | gray=100%, others=91.7% (FP 부분 존재) |
| Exp58 주석 | 5/28 | V4 brown pot pseudo-label 생성 | 524/524 에피소드 완료 |
| Exp59 Cross-Object | 5/28~29 | Hard Negative 4종 분리 검증 | TP=95%, FP=0.0% ✅ |
| Exp59 CL (진행 중) | 5/29 | Closed-Loop 시뮬레이션 | Grounding 98%, CL 4.5% (노이즈 분석 중) |
| 다중 스케일 차폐 스윕 | 6/3 | 차폐 배율/색상별 인과성 분석 | 1.0x 이하 Flip 0% (안정) / 검은색 Conf Drop 2.9배 |
| 배경 역-마스킹 및 블러 | 6/3 | 배경 차폐/블러링을 통한 암기 여부 검증 | 배경 차폐 0% 붕괴 / 블러 주입 88.9% 강건 |
| Y-Center STOP Gate | 6/3 | BBox Y-Center 기반 정지 제약 검증 | CL 성공률 34.4% ➔ 68.8% (2.0배 향상) |
docs/v5/PROF_QA_EVIDENCE_20260529.md · 최종 업데이트: 2026-06-03 11:00 KST최근 수행: 1.0x 마스킹 인과성 규명 및 도착 STOP Gate 물리 시각화 이식 완료